中文編碼方案中最有名的就是GB2312,它是中國國家標準總局于1980年發布,并于1981年5月1日實施的。除中國外,新加坡等地也采用此編碼。可以說GB2312是中文編碼的基石,后續基本都是對它的補充和升級。它共收入了6763個漢字,包括一級漢字3755個(最常用的),二級漢字3008個(比較常用的)。同時收入了拉丁字母、希臘字母、日本片假名、注音符號、西里爾字母等總計682個字符。之前介紹的泰國字符集和歐美字符集都是使用16×16的表格,GB2312也是類似的,但是因為它的字符數量非常多(和歐美等相比),所以它使用的是一個94×94的表格。GB2312編碼的每一個字符都在這個表格里,為了方便,這個表格的行號我們稱為區碼(從1開始),列號我們稱為位碼(從1開始)。這實際上就是每行是一個區。連續的幾個區因為保存的字符的關聯性,我們又把把所有區分為了幾個區段:
- 01~09區:用于存放拉丁字母、希臘字母、日本片假名、注音符號、西里爾字母等總計682個字符。注意,原則上一個有846(94×9)個位置,但只使用了682個。
- 10~15區:空區,預留,為后續擴展。但實際上,10區和11區已經使用了(這個內容可以參考附錄部分)。
- 16~55區:最常用的、一級漢字,共3755個,按拼音排序(新華字典就是這種排序方式)。
- 56~87區:比較常用的,二級漢字,共3008個,按部首/筆畫排序(康熙字典就是這種排序方式)。
- 88~94區:空區,預留。目前還沒有啟用,估計后續也不會啟用了。
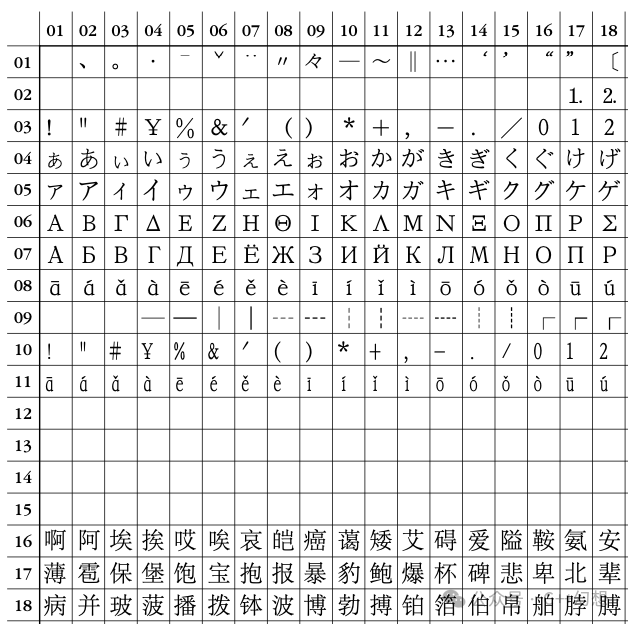
下圖(圖1)為編碼的局部示意圖(完整的太大了,就不展示了,有需要的可以參考附錄部分):上圖中,第17行,第6列的字——寶,編碼就應該是:區碼為17(十六進制為11),位碼為6(十六進制為06),所以,“寶”這個字的編碼(十六進制)就是11 06。PS: 序列化的含義是,存儲化,就是轉換為一個連續的內存的過程,文字保存(到磁盤等)和網絡傳輸,使用的都是序列化后的數據。最簡單的一個轉碼方案稱為國標碼,也叫交換碼。轉換方法是區碼和位碼分別加上32,也就是十六進制的20,這樣,“寶”這個字的交換碼(十六進制)就是13 08。當然,現在最常用的是機內碼,也叫內碼。轉換方法是區碼和位碼分別加上160(相對于GB2312),也就是十六進制的A0,這樣,“寶”這個字的內碼(十六進制)就是B1 A6。在現代計算機中,基本使用的都是內碼。如果,把一個文件編碼為GB2312后,如果內容只有一個字——寶,那么,你用二進制工具打開后,看到的通常都是 B1 A6。內碼的本質,要說這個問題,要先說交換碼的目的。本文后續部分,說的都是十六進制的數。交換碼是為了避開ASCII字符中的不可顯示字符(00到1F)和空格(20)。這樣,區碼和位碼都加20,(區碼和位碼)就避開了它們。這樣,區碼和位碼的有效區間就都是[21, 7E]。注意,有趣的點來了,這個使用7位就可以保存了,而計算機的一字節有8位,那么,把交換碼的第8位設置為1,就能和ASCII完美避開了。原來第8位為0,變成1的本質就是加上80。這樣,加上20,然后再加上80,這不就是加上A0。目前,看到的GB2312編碼實際上都是GB2312編碼的內碼。總結一下:原始的GB2312編碼中,區碼和位碼的有效區間就都是[01, 5E]。GB2312交換碼中,區碼和位碼的有效區間就都是[21, 7E]。原始的GB2312內碼中,區碼和位碼的有效區間就都是[A1, FE]。在實際的使用中,GB2312通常是使用內碼,例如:“寶” 這個字的GB2312編碼(十六進制)就是 B1 A6,而不會稱GB2312內碼,或者真的轉為GB2312編碼的 11 06。真正的GB2312(內碼)也已經很難看到了,更常見的是GBK(哪怕是GB2312,也可能標識為GBK)。下次,我們就一起看一下GBK編碼。
閱讀原文:原文鏈接
該文章在 2025/4/18 11:49:56 編輯過






 400 186 1886
400 186 1886